Transformation
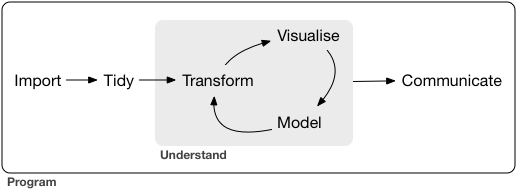
Preamble
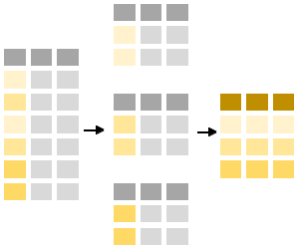
Commonly, when collating summaries by group, one wants to:
- Split up a big data structure into homogeneous pieces,
- Apply a function to each piece
- Combine all the results back together.
Reading material
Libraries and data
library(tidyverse)
w <- read_csv("ftp://ftp.hafro.is/pub/data/csv/minke.csv")Summarise cases
summarise:
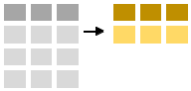
To summarise data one uses the summarise-function. Below we calculate the number of observations (using the n-function and the mean minke length.
w |>
summarise(n.obs = n(),
ml = mean(length, na.rm = TRUE))# A tibble: 1 × 2
n.obs ml
<int> <dbl>
1 190 753.group_by:
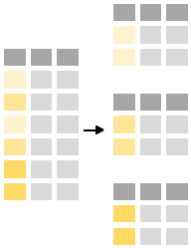
The power of the command summarise is revealed when used in conjunction with group_by-function. The latter functions splits the data into groups based on one or multiple variables. E.g. one can split the minke table by maturity:
w |>
group_by(maturity)# A tibble: 190 × 13
# Groups: maturity [6]
id date lon lat area length weight age sex
<dbl> <dttm> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <chr>
1 1 2004-06-10 22:00:00 -21.4 65.7 North 780 NA 11.3 Female
2 690 2004-06-15 17:00:00 -21.4 65.7 North 793 NA NA Female
3 926 2004-06-22 01:00:00 -19.8 66.5 North 858 NA 15.5 Female
4 1333 2003-09-30 16:00:00 -21.6 65.7 North 567 NA 7.2 Male
5 1334 2003-09-25 15:00:00 -15.6 66.3 North 774 NA 12.3 Female
6 1335 2003-09-16 16:00:00 -18.7 66.2 North 526 NA 9.6 Female
7 1336 2003-09-12 17:00:00 -21.5 65.7 North 809 NA 17.3 Female
8 1338 2003-09-09 12:00:00 -22.8 66.1 North 820 NA 13.8 Female
9 1339 2003-08-31 13:00:00 -17.5 66.6 North 697 NA 12.2 Male
10 1341 2003-08-30 17:00:00 -14.7 66.2 North 777 NA 15.4 Male
# ℹ 180 more rows
# ℹ 4 more variables: maturity <chr>, stomach.volume <dbl>,
# stomach.weight <dbl>, year <dbl>The table appears “intact” because it still has 190 observations but it has 6 groups, representing the different values of the maturity scaling in the data (anoestrous, immature, mature, pregnant, pubertal and “NA”).
The summarise-command respects the grouping, as shown if one uses the same command as used above, but now on a dataframe that has been grouped:
w |>
group_by(maturity) |>
summarise(n.obs = n(),
mean = mean(length))# A tibble: 6 × 3
maturity n.obs mean
<chr> <int> <dbl>
1 anoestrous 6 784.
2 immature 25 619.
3 mature 74 758.
4 pregnant 66 800.
5 pubertal 6 692.
6 <NA> 13 752.- Calculate the number of observations and minimum, median, mean, standard deviation and standard error of whale lengths in each year
- The function names in R are:
- n
- min
- max
- median
- mean
- sd
The function for standard error is not availble in R. A remedy is that you use college statistical knowledge to derive them from the appropriate variables you derived above.
w |>
group_by(year) |>
summarise(n = n(),
min = min(length),
max = max(length),
median = median(length),
mean = mean(length),
sd = sd(length),
se = sd / sqrt(n))Note: If you would not be using the pipe-code-flow your code would be something like this:
summarise(group_by(w, year),
n = n(),
min = min(length)) # etc.Shown because you are bound to come accross code like this.
Joins
Normally the data we are interested in working with do not reside in one table. E.g. for a typical survey data one stores a “station table” separate from a “detail” table. The surveys could be anything, e.g. catch sampling at a landing site or scientific trawl or UV-surveys.
Lets read in the Icelandic groundfish survey tables in such a format:
station <-
read_csv("ftp://ftp.hafro.is/pub/data/csv/is_smb_stations.csv")
biological <-
read_csv("ftp://ftp.hafro.is/pub/data/csv/is_smb_biological.csv")
station %>% select(id:lat1) %>% arrange(id) %>% glimpse()Rows: 19,846
Columns: 9
$ id <dbl> 29654, 29655, 29656, 29657, 29658, 29659, 29660, 29661, 29662, …
$ date <date> 1985-03-21, 1985-03-20, 1985-03-20, 1985-03-20, 1985-03-20, 19…
$ year <dbl> 1985, 1985, 1985, 1985, 1985, 1985, 1985, 1985, 1985, 1985, 198…
$ vid <dbl> 1273, 1273, 1273, 1273, 1273, 1273, 1273, 1273, 1273, 1273, 127…
$ tow_id <chr> "374-3", "374-11", "374-12", "373-13", "373-11", "373-12", "373…
$ t1 <dttm> 1985-03-21 00:45:00, 1985-03-20 22:25:00, 1985-03-20 20:35:00,…
$ t2 <dttm> 1985-03-21 01:50:00, 1985-03-20 23:25:00, 1985-03-20 21:45:00,…
$ lon1 <dbl> -24.17967, -24.19783, -24.40467, -23.99833, -23.67983, -23.7210…
$ lat1 <dbl> 63.96350, 63.75367, 63.71817, 63.58000, 63.74767, 63.83767, 63.…biological %>% arrange(id) %>% glimpse() Rows: 68,834
Columns: 4
$ id <dbl> 29654, 29654, 29654, 29654, 29655, 29655, 29655, 29655, 29656,…
$ species <chr> "cod", "haddock", "saithe", "wolffish", "cod", "haddock", "sai…
$ kg <dbl> 53.4895900, 29.6435494, 22.8682684, 0.6901652, 29.6210500, 203…
$ n <dbl> 13, 15, 5, 1, 6, 155, 23, 4, 6, 156, 39, 4, 43, 421, 8, 11, 25…Here the information on the station, such as date, geographical location are kept separate from the detail measurments that are performed at each station (weight and numbers by species). The records in the station table are unique (i.e. each station information only appear once) while we can have more than one species measured at each station. Take note here that the biological table does not contain records of species that were not observed at that station. The link between the two tables, in this case, is the variable id.
left_join: Matching values from y to x
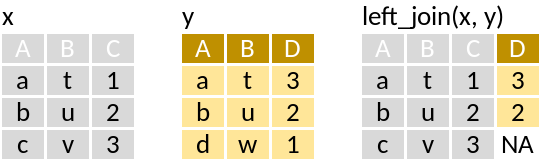
Lets say we were interested in combining the geographical position and the species records from one station:
station %>%
select(id, date, lon1, lat1) %>%
filter(id == 29654) %>%
left_join(biological)# A tibble: 4 × 7
id date lon1 lat1 species kg n
<dbl> <date> <dbl> <dbl> <chr> <dbl> <dbl>
1 29654 1985-03-21 -24.2 64.0 cod 53.5 13
2 29654 1985-03-21 -24.2 64.0 haddock 29.6 15
3 29654 1985-03-21 -24.2 64.0 saithe 22.9 5
4 29654 1985-03-21 -24.2 64.0 wolffish 0.690 1Take note here:
- The joining is by common variable name in the two tables (here id)
- That we only have records of fours species in this table, i.e. a value of zero for a species is not stored in the data.
right_join: Matching values from x to y
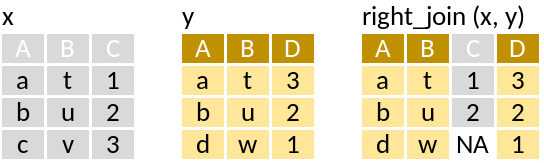
This is really the inverse of left_join.
inner_join: Retain only rows with matches
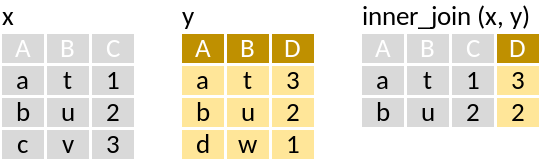
Example of only joining station information with monkfish, were monkfish was recorded:
station %>%
inner_join(biological %>%
filter(species == "monkfish"))# A tibble: 2,038 × 31
id date year vid tow_id t1 t2
<dbl> <date> <dbl> <dbl> <chr> <dttm> <dttm>
1 44154 1990-03-11 1990 1273 374-1 1990-03-11 10:25:00 1990-03-11 11:30:00
2 44271 1990-03-12 1990 1273 323-1 1990-03-12 09:15:00 1990-03-12 10:25:00
3 44382 1990-03-13 1990 1273 320-4 1990-03-13 14:20:00 1990-03-13 15:20:00
4 44156 1990-03-11 1990 1273 374-3 1990-03-11 07:10:00 1990-03-11 08:15:00
5 44379 1990-03-14 1990 1273 320-3 1990-03-14 01:40:00 1990-03-14 02:40:00
6 44377 1990-03-14 1990 1273 320-12 1990-03-14 05:45:00 1990-03-14 06:50:00
7 44375 1990-03-14 1990 1273 321-11 1990-03-14 09:30:00 1990-03-14 10:40:00
8 44373 1990-03-14 1990 1273 371-12 1990-03-14 13:30:00 1990-03-14 14:20:00
9 44356 1990-03-16 1990 1273 366-11 1990-03-16 00:50:00 1990-03-16 01:30:00
10 50775 1992-03-15 1992 1273 371-12 1992-03-15 09:00:00 1992-03-15 10:10:00
# ℹ 2,028 more rows
# ℹ 24 more variables: lon1 <dbl>, lat1 <dbl>, lon2 <dbl>, lat2 <dbl>,
# ir <chr>, ir_lon <dbl>, ir_lat <dbl>, z1 <dbl>, z2 <dbl>, temp_s <dbl>,
# temp_b <dbl>, speed <dbl>, duration <dbl>, towlength <dbl>,
# horizontal <dbl>, verical <dbl>, wind <dbl>, wind_direction <dbl>,
# bormicon <dbl>, oldstrata <dbl>, newstrata <dbl>, species <chr>, kg <dbl>,
# n <dbl>full_join: Retain all rows
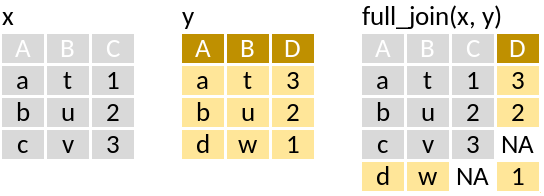
station %>%
full_join(biological %>%
filter(species == "monkfish")) %>%
select(id, species:n)# A tibble: 19,846 × 4
id species kg n
<dbl> <chr> <dbl> <dbl>
1 44929 <NA> NA NA
2 44928 <NA> NA NA
3 44927 <NA> NA NA
4 44926 <NA> NA NA
5 44925 <NA> NA NA
6 44922 <NA> NA NA
7 44921 <NA> NA NA
8 44920 <NA> NA NA
9 44919 <NA> NA NA
10 44918 <NA> NA NA
# ℹ 19,836 more rowsHere all the stations records are retained irrepsective if monkfish was caught or not.
Run through this set of code that supposedly mimics the pictograms above:
x <- tibble(A = c("a", "b", "c"),
B = c("t", "u", "v"),
C = c(1, 2, 3))
y <- tibble(A = c("a", "b", "d"),
B = c("t", "u", "w"),
D = c(3, 2, 1))
left_join(x, y)
right_join(x, y)
left_join(y, x)
inner_join(x, y)
full_join(x, y)Combine cases (bind)
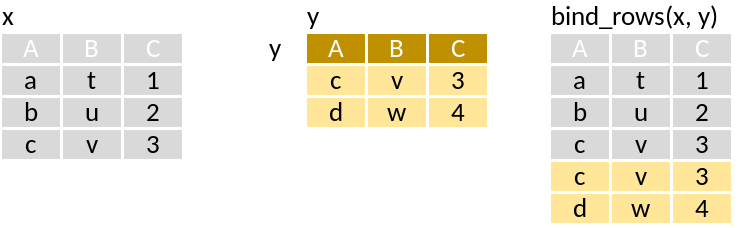
bind_rows: One on top of the other as a single table.
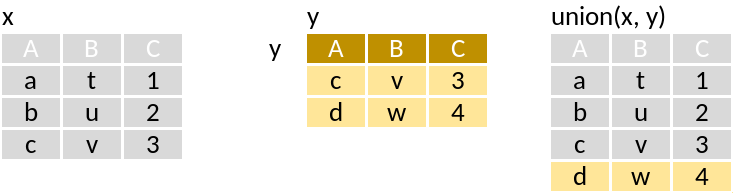
union: Rows in x or y
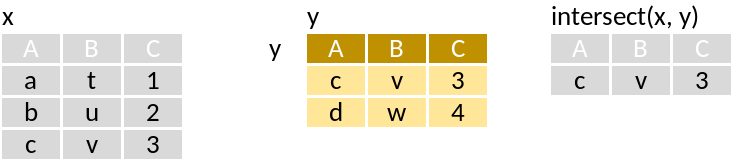
intersect: Rows in x and y.
setdiff: Rows in x but not y
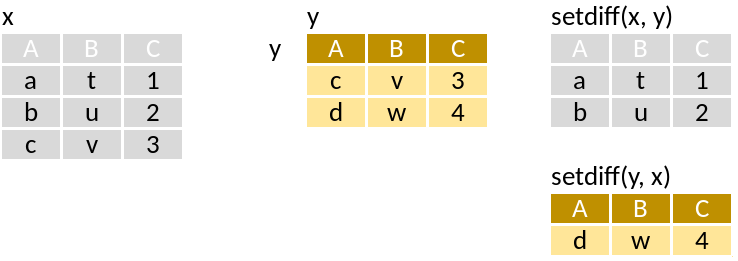
Run through this set of code that supposedly mimics the pictograms above:
x <- tibble(A = c("a", "b", "c"),
B = c("t", "u", "v"),
C = c(1, 2, 3))
y <- tibble(A = c("c", "d"),
B = c("v", "w"),
C = c(3, 4))
bind_rows(x, y)
union(x, y)
intersect(x, y)
setdiff(x, y)
setdiff(y, x)