Exploratory data analysis fall under the umbrella of tidying, transforming, visualization and possibly modelling. EDA involves among other things:
Familiarization of the data
Detecting patterns and trends
You may discover some new patterns in your own data
A precursor to hypothesis testing
In this section we are going to use the Icelandic trawl groundfish survey as a case example in EDA, covering some transformations and more visualization techniques along the way.
The survey falls under the realm of standardized scientific survey where the idea is that the gear design and the effort is kept as constant as possible over the years with the output then being survey indicies to be used as input into stock assessment.
The concept with the code below is to present the idea that one can extract information, knowledge and pattern in the data without much external knowledge. That said knowing your data, sampling design, including potential pitfalls. shortcomings, etc. is vital.
Ad hoc EDA
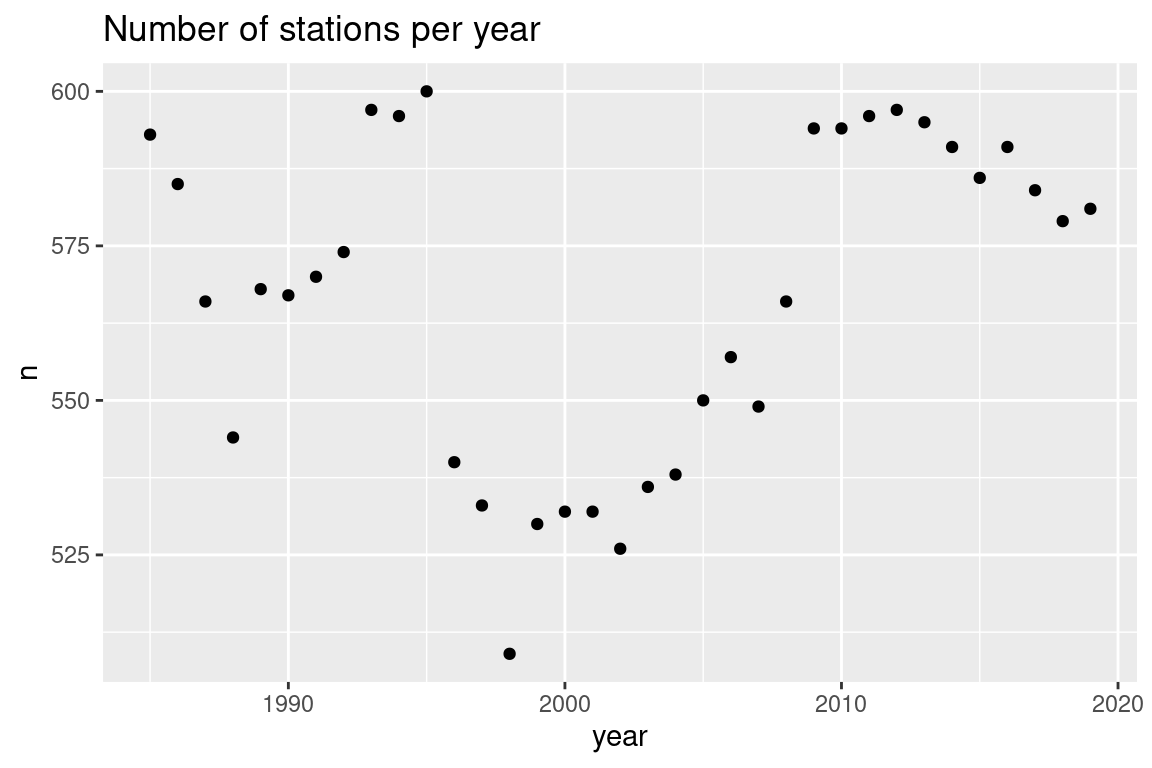
# Import -----------------------------------------------------------------------library(tidyverse)s <-read_csv("ftp://ftp.hafro.is/pub/data/csv/is_smb_stations.csv")b <-read_csv("ftp://ftp.hafro.is/pub/data/csv/is_smb_biological.csv")# Counts -----------------------------------------------------------------------## Number of stations ----------------------------------------------------------s |>count(year) |>ggplot(aes(year, n)) +geom_point() +labs(title ="Number of stations per year")
## When in year ----------------------------------------------------------------s |>mutate(month =month(date)) |>count(month)
# A tibble: 3 × 2
month n
<dbl> <int>
1 2 544
2 3 19266
3 4 36
## What vessels ----------------------------------------------------------------s |>count(vid)
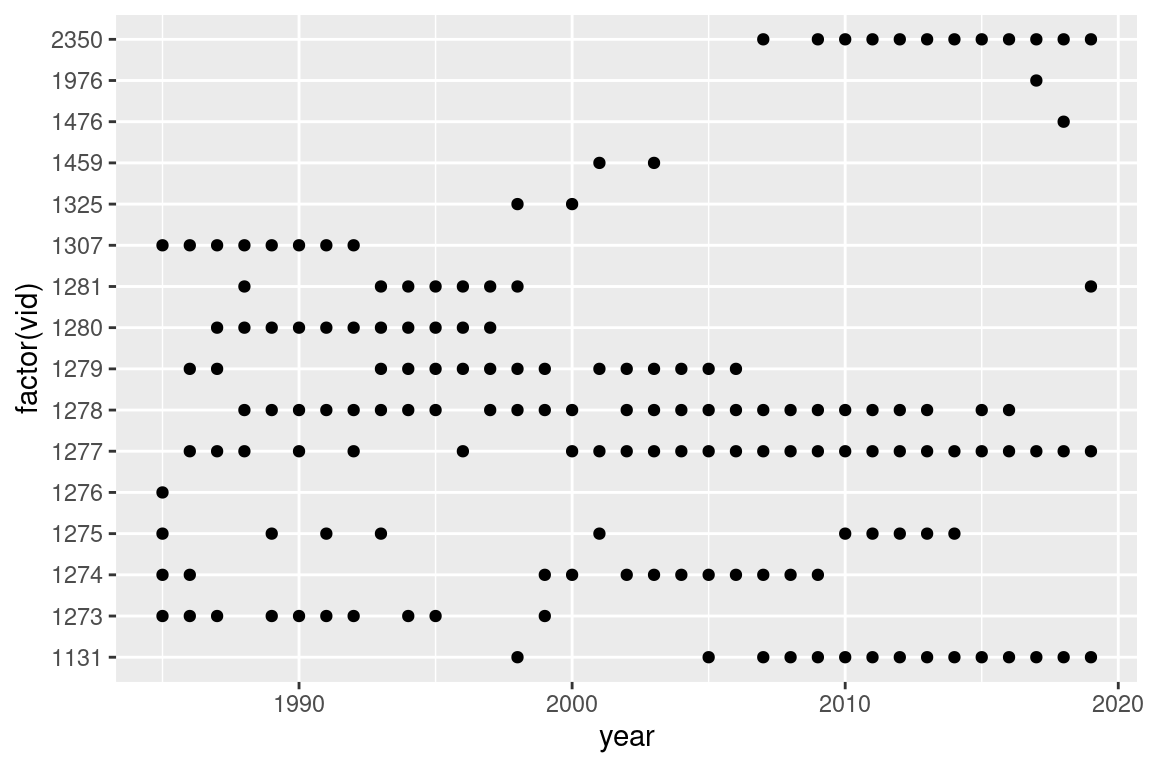
## When vessels ----------------------------------------------------------------s |>count(vid, year) |>ggplot(aes(year, factor(vid))) +geom_point()
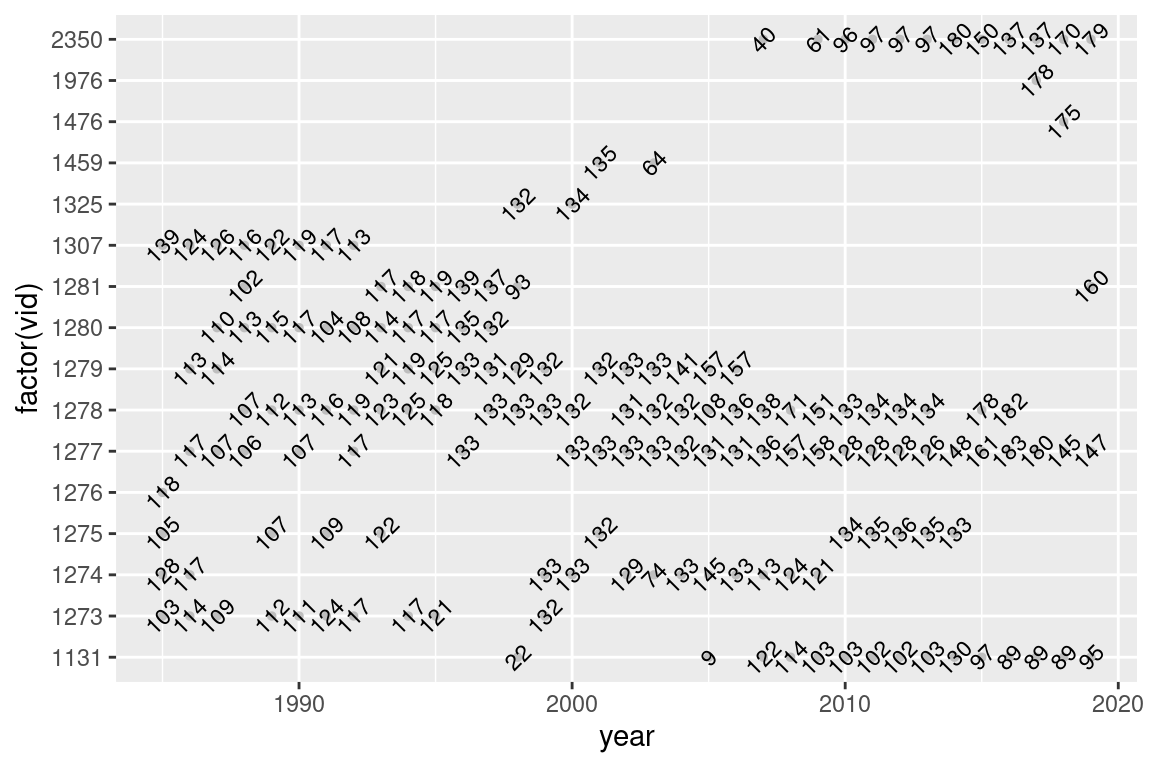
# Add informations on number of towss |>count(vid, year) |>ggplot(aes(year, factor(vid), label = n)) +geom_point(colour ="grey", size =1) +# size: control point sizegeom_text(angle =45, size =3) # size: control text size
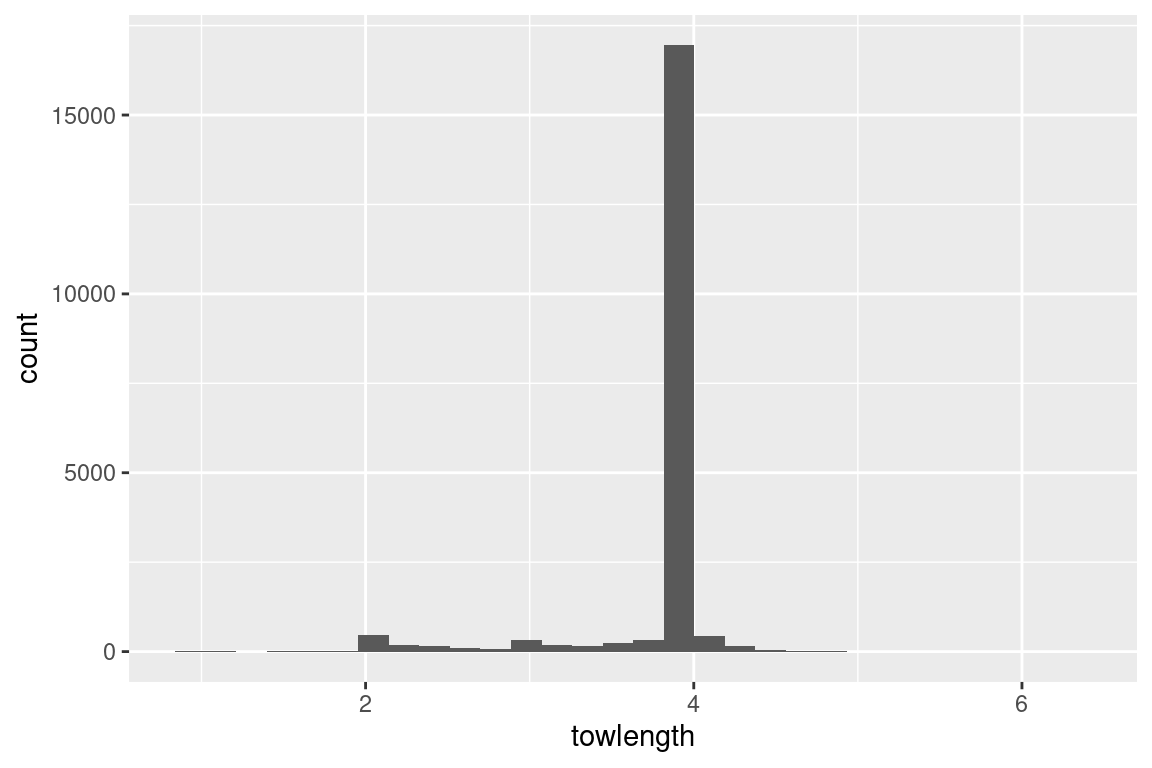
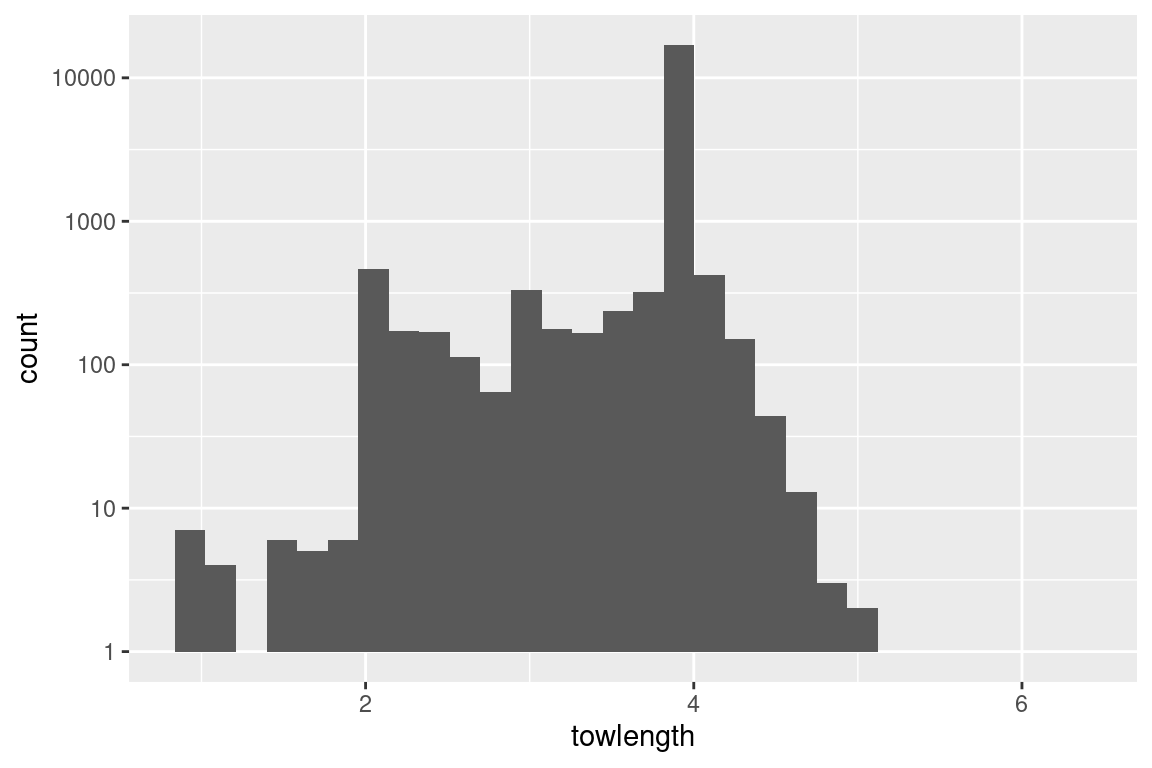
# change y-axis scale to get a better view of the smaller observationss |>ggplot(aes(towlength)) +geom_histogram() +scale_y_log10()
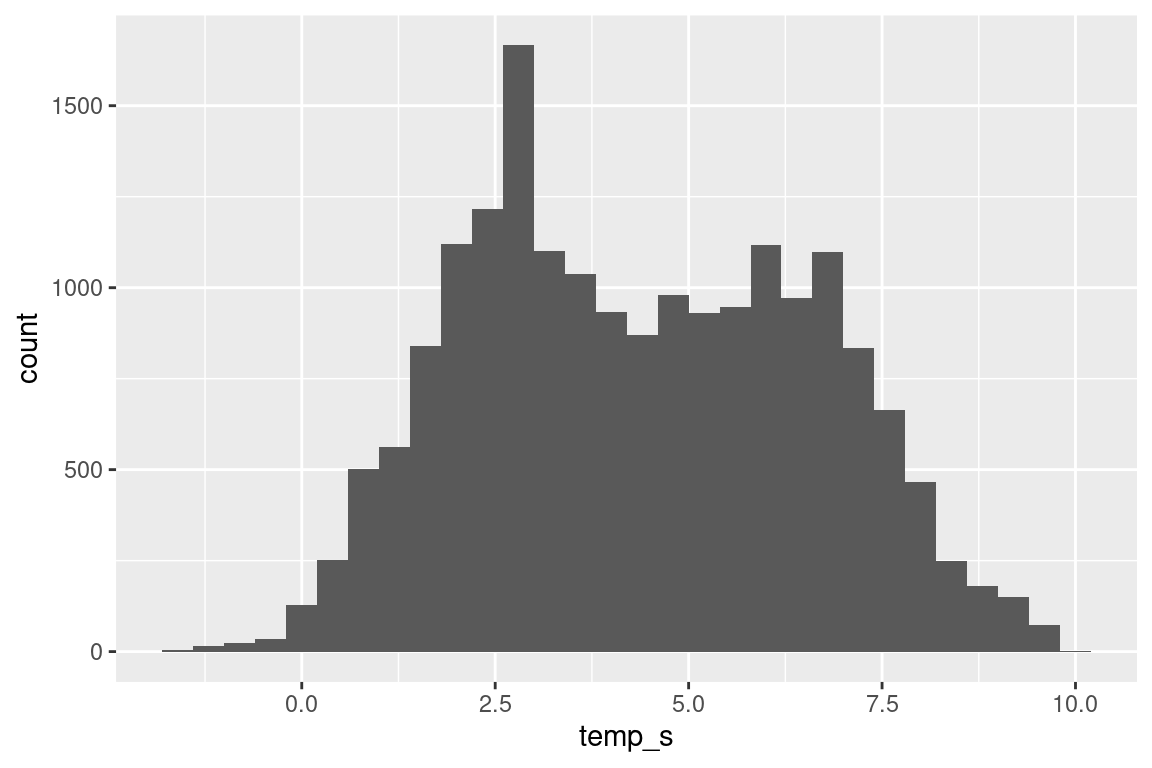
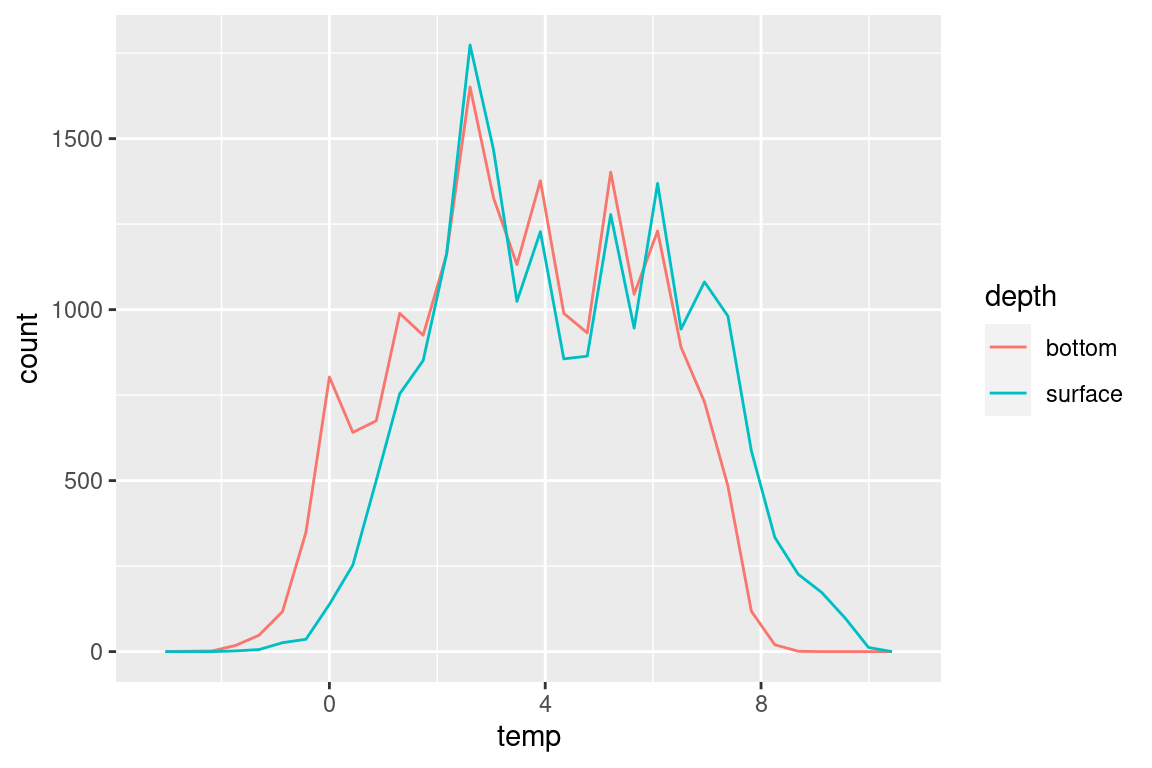
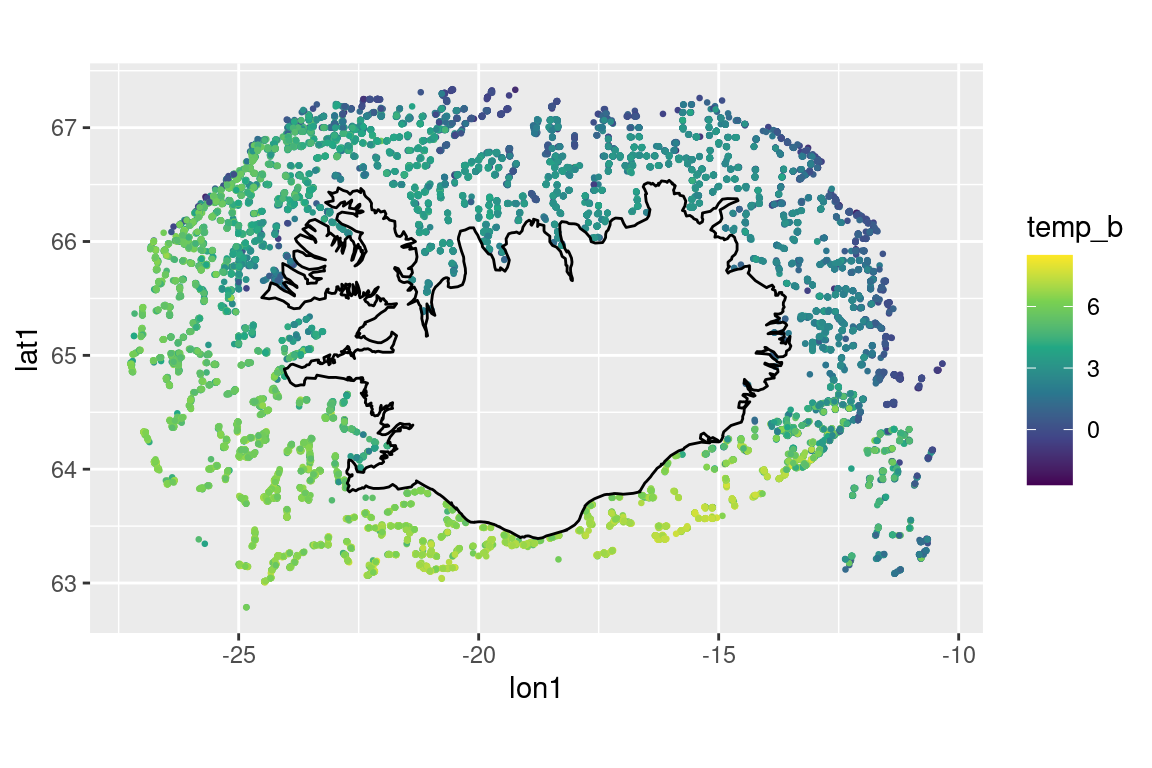
# what is the maximum towlength?# max(s$towlength, na.rm = TRUE) # 6.4# Note: this maxmimum tow length does not show up in the histogram plots## Temperature -----------------------------------------------------------------# surfaces |>ggplot(aes(temp_s)) +geom_histogram()
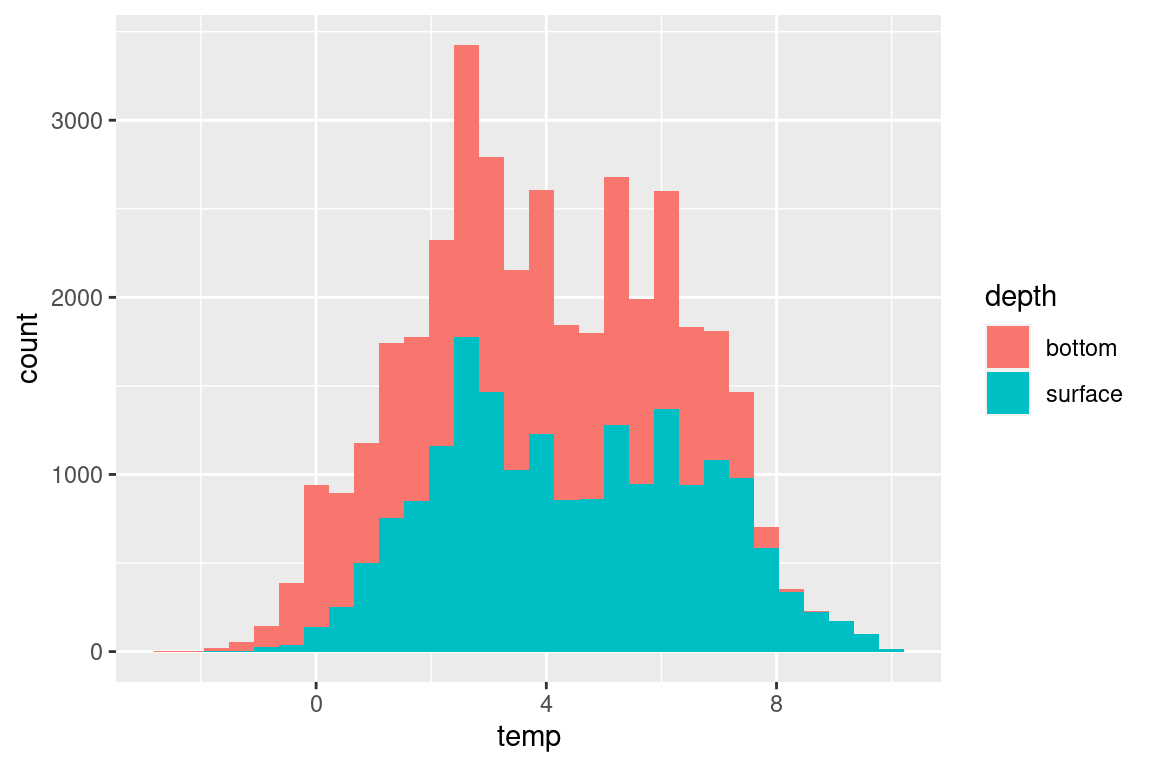
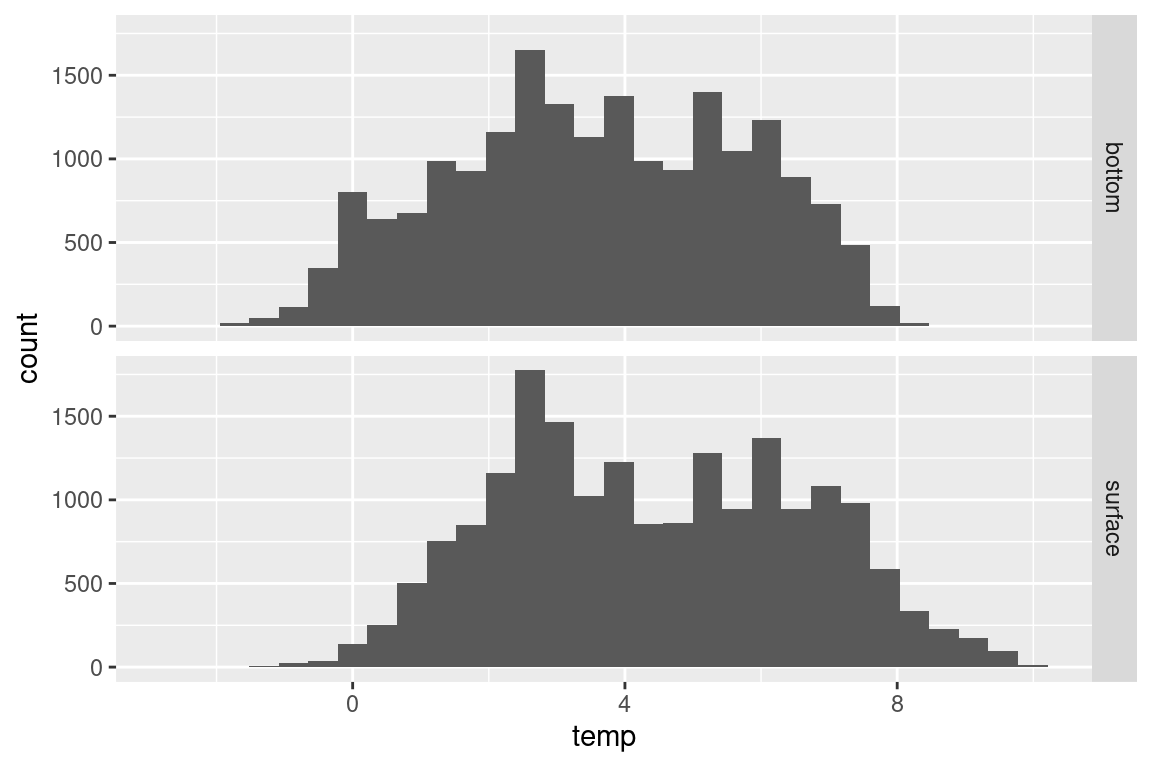
# both surface and bottom temperaturetmp <- s |>select(year, temp_s, temp_b) |>pivot_longer(cols = temp_s:temp_b, names_to ="depth", values_to ="temp") |>mutate(depth =case_when(depth =="temp_s"~"surface", depth =="temp_b"~"bottom"))tmp
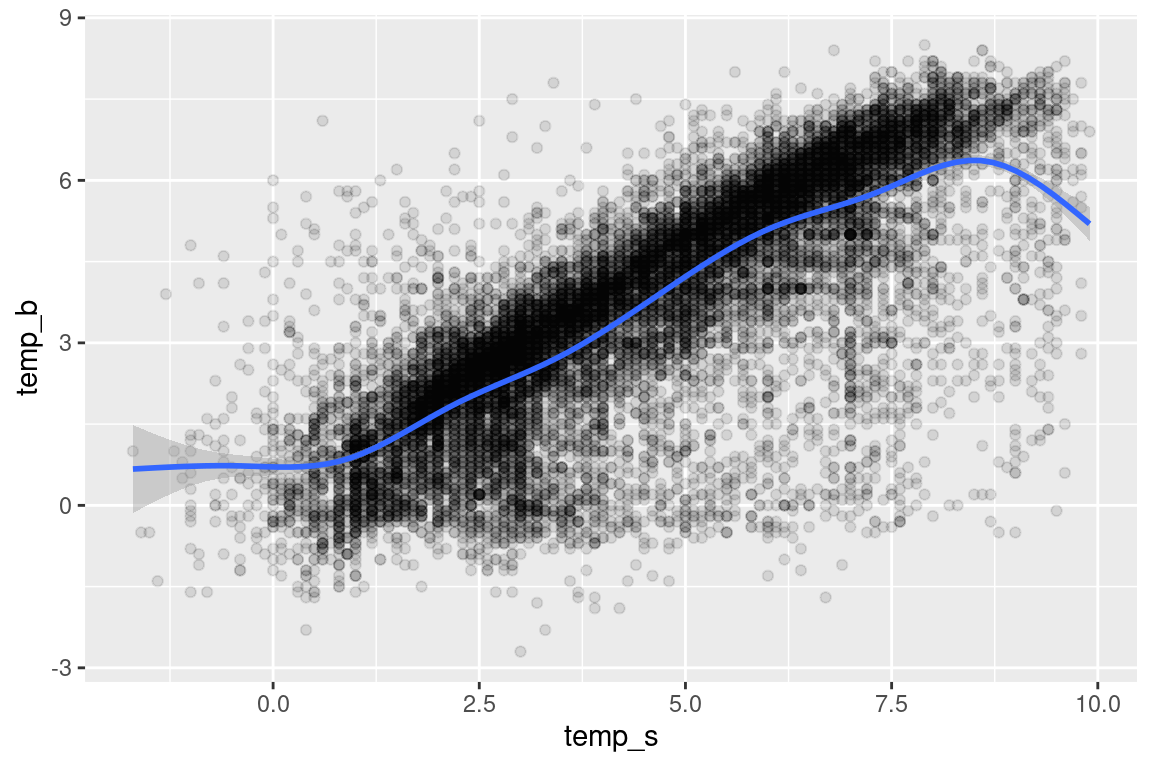
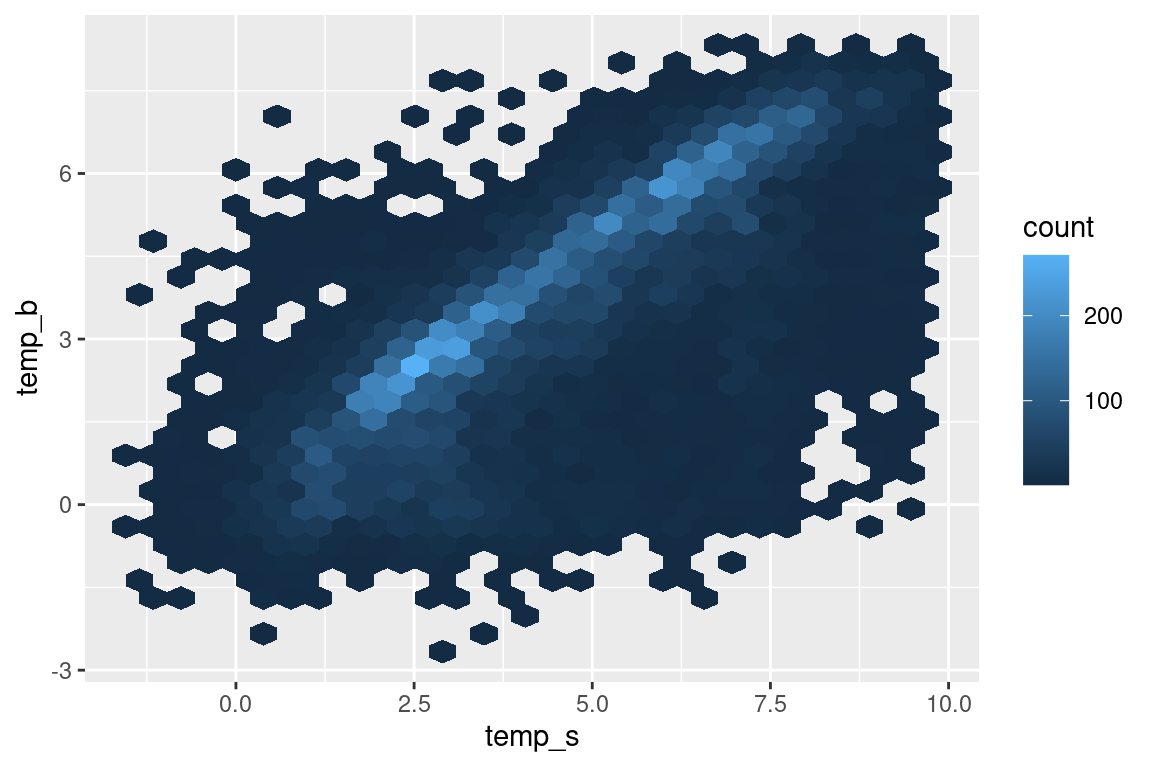
s |>ggplot(aes(temp_s, temp_b)) +geom_hex() # geom_hex provides number of observations within bins
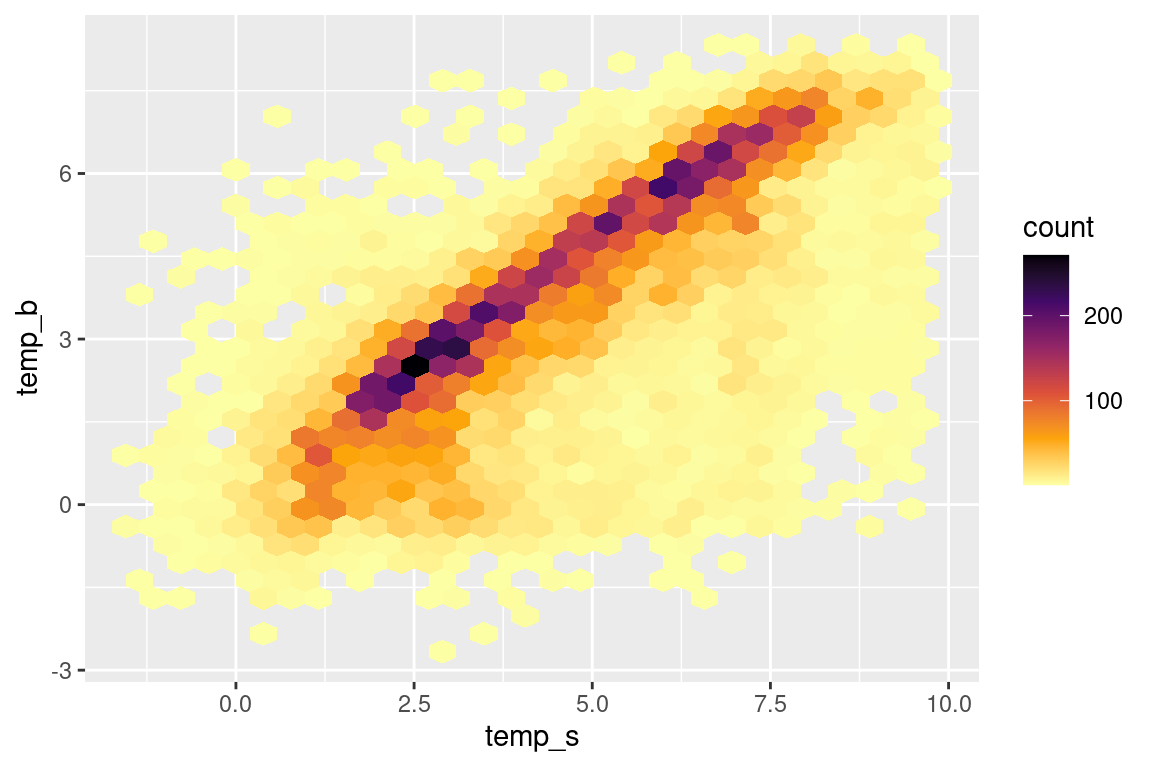
# overwrite the default colours |>ggplot(aes(temp_s, temp_b)) +geom_hex() +scale_fill_viridis_c(option ="B", direction =-1)
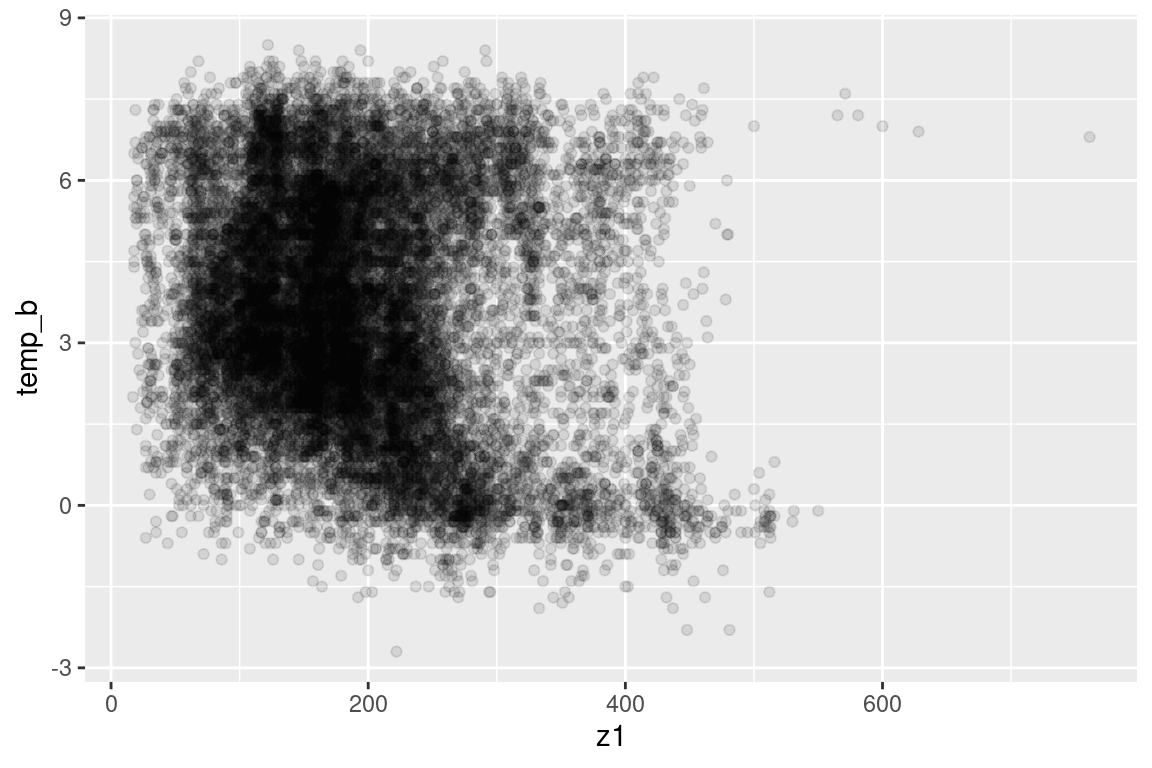
## Temperature vs depth --------------------------------------------------------s |>ggplot(aes(z1, temp_b)) +geom_point(alpha =0.1)
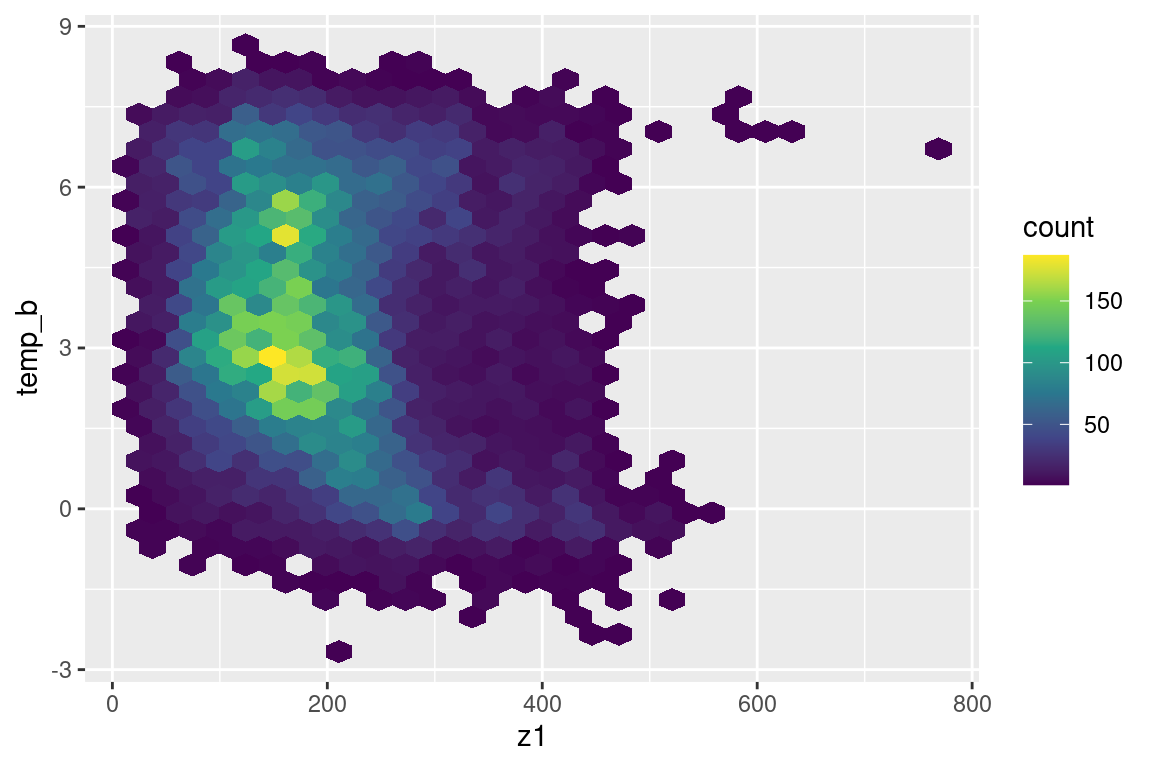
s |>ggplot(aes(z1, temp_b)) +geom_hex() +scale_fill_viridis_c()
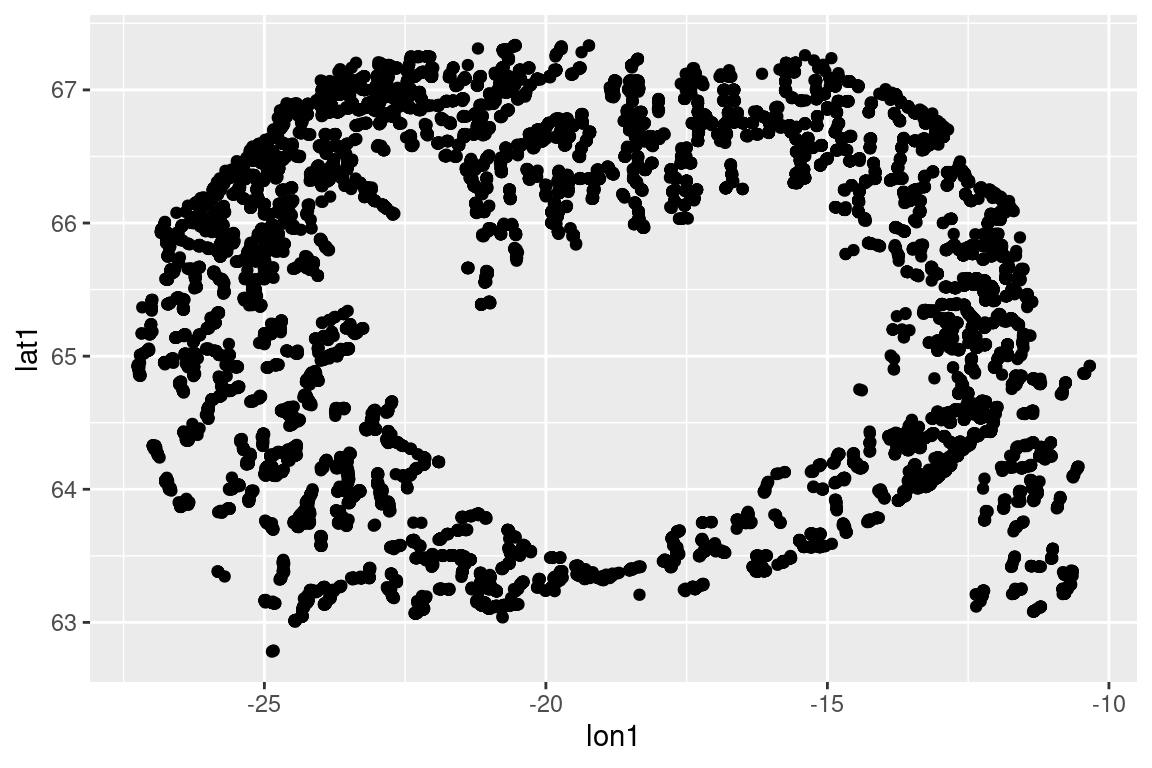
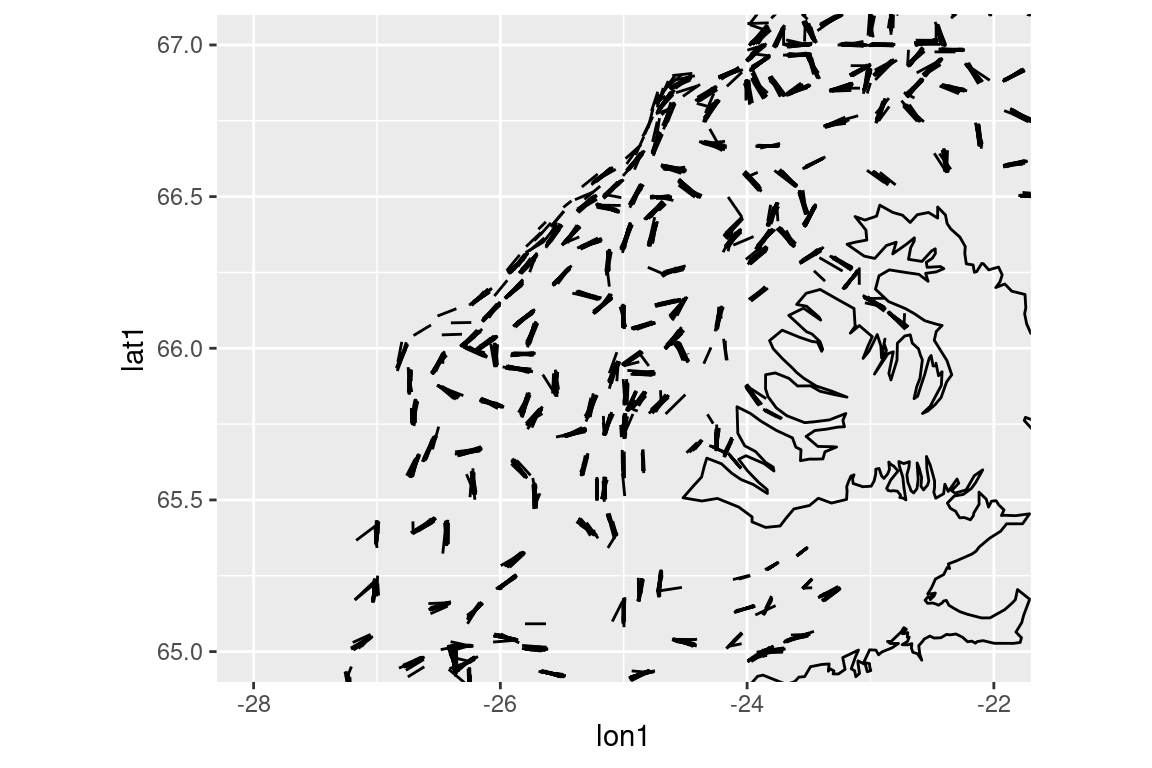
# Spatial stuff ----------------------------------------------------------------## Tow locations ----------------------------------------------------------------# Just the starting points |>ggplot(aes(lon1, lat1)) +geom_point()
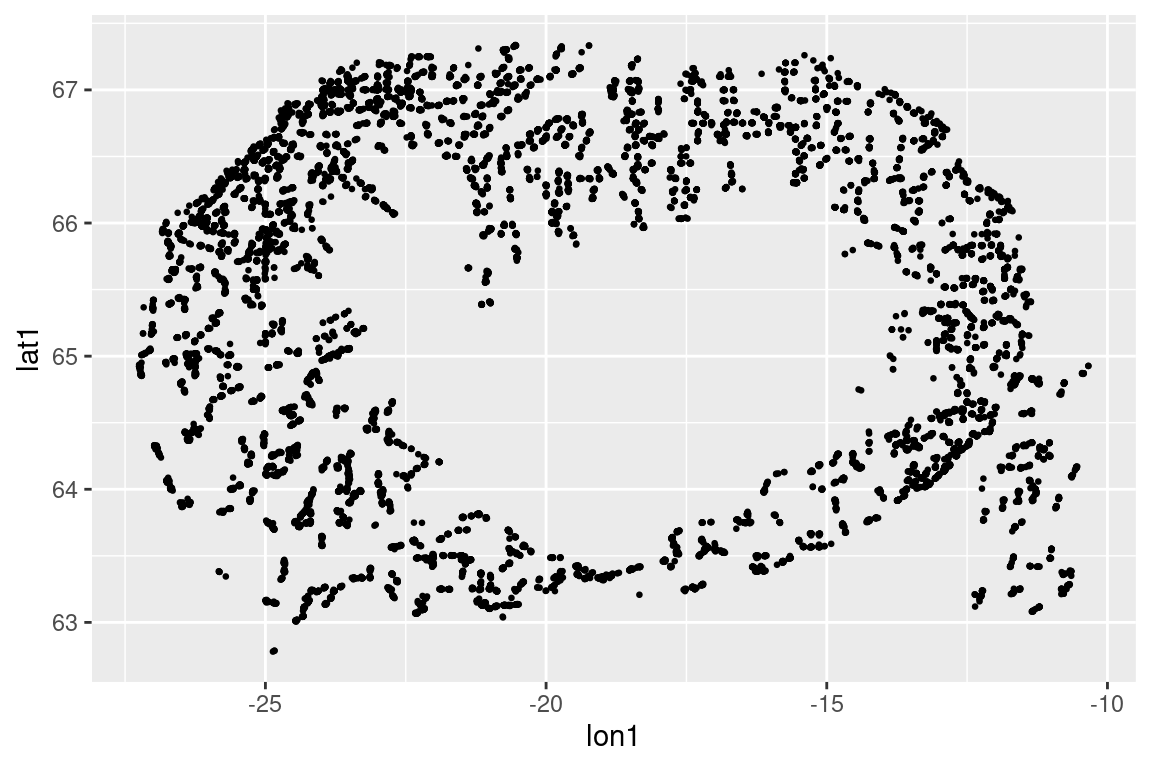
# Get the aspect ratio roughly rights |>ggplot(aes(lon1, lat1)) +geom_point(size =0.5) +coord_quickmap()
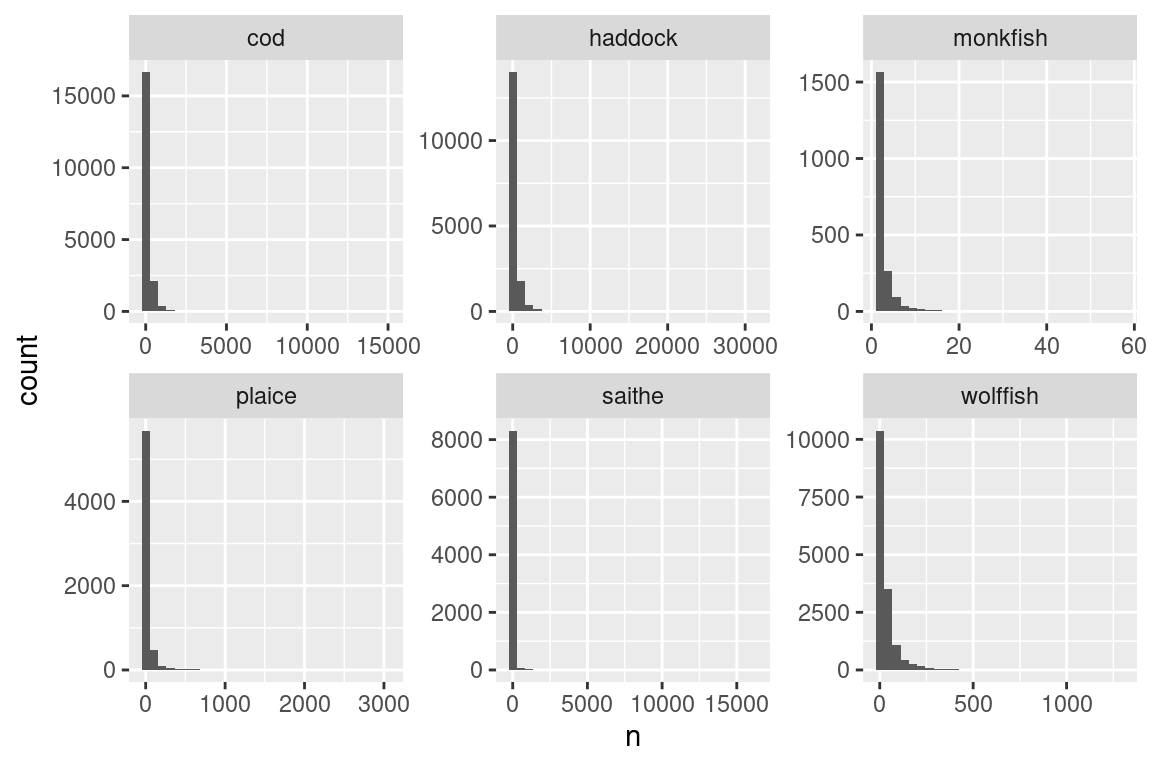
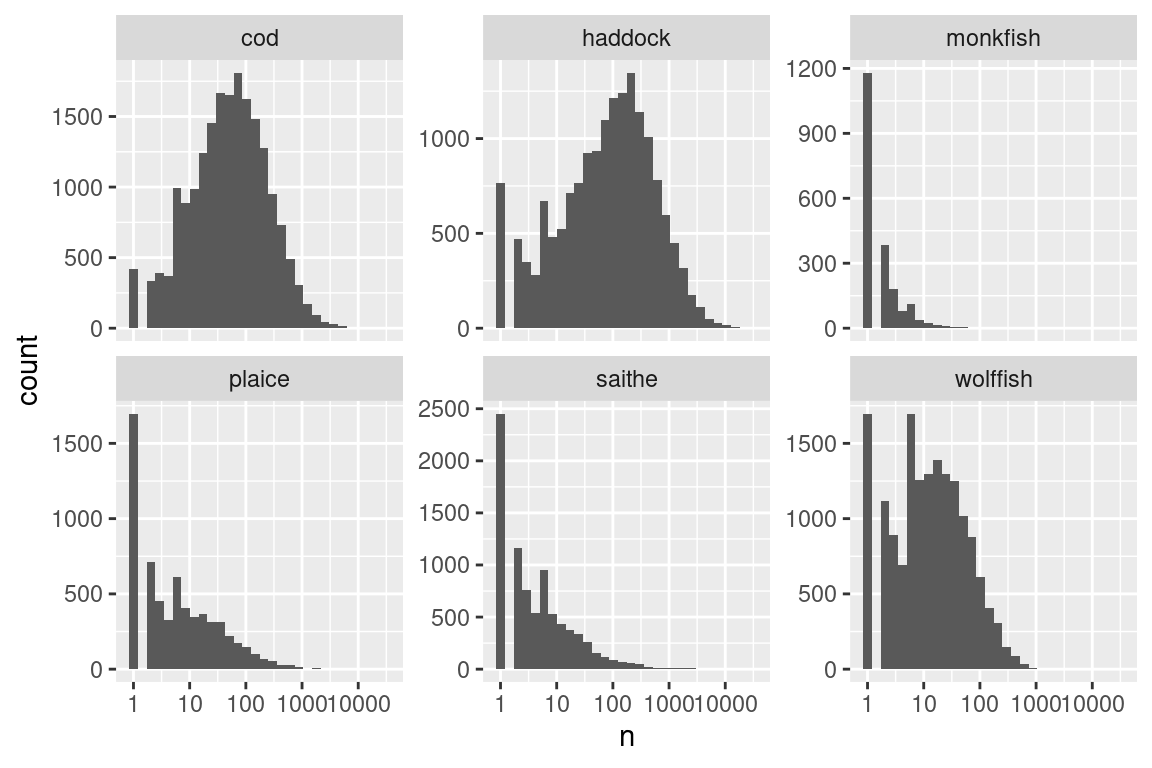
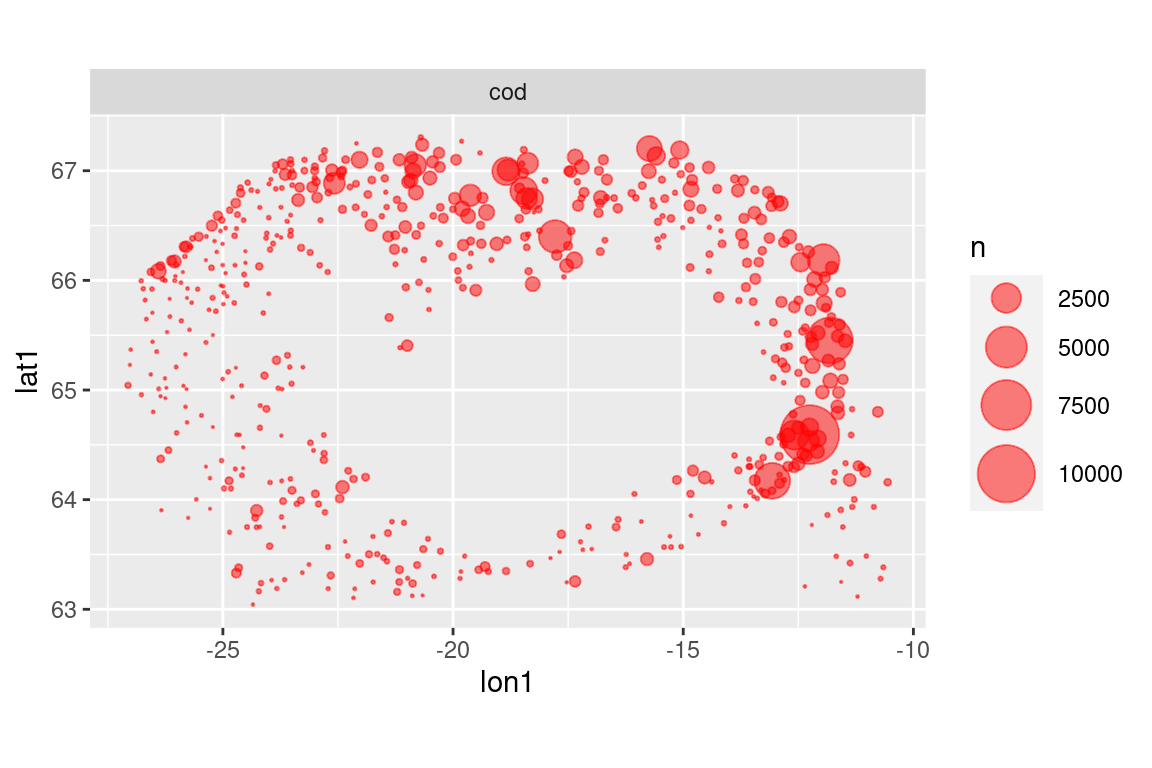
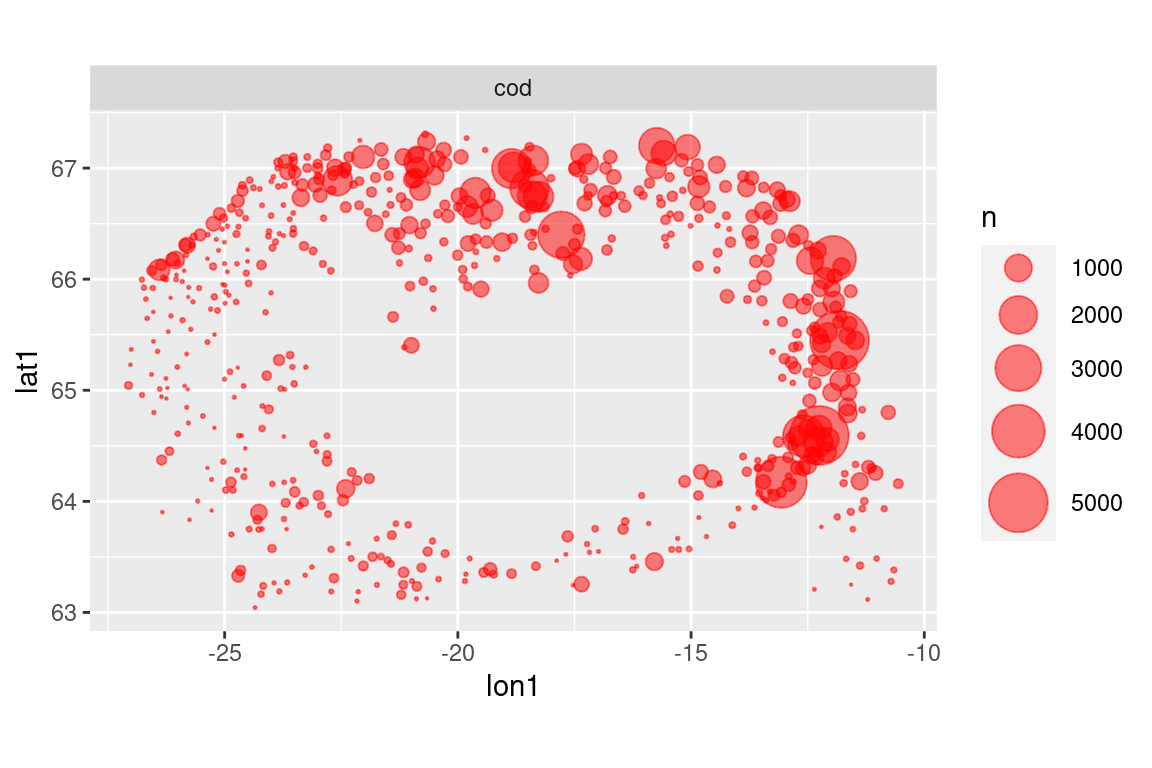
# put some upper cap on datas |>filter(year ==2012) |>select(id, lon1, lat1) |>left_join(b) |>filter(species =="cod") |>mutate(n =ifelse(n >5000, 5000, n)) |>ggplot() +geom_point(aes(lon1, lat1, size = n), colour ="red", alpha =0.5) +scale_size_area(max_size =10) +facet_wrap(~ species) +coord_quickmap()
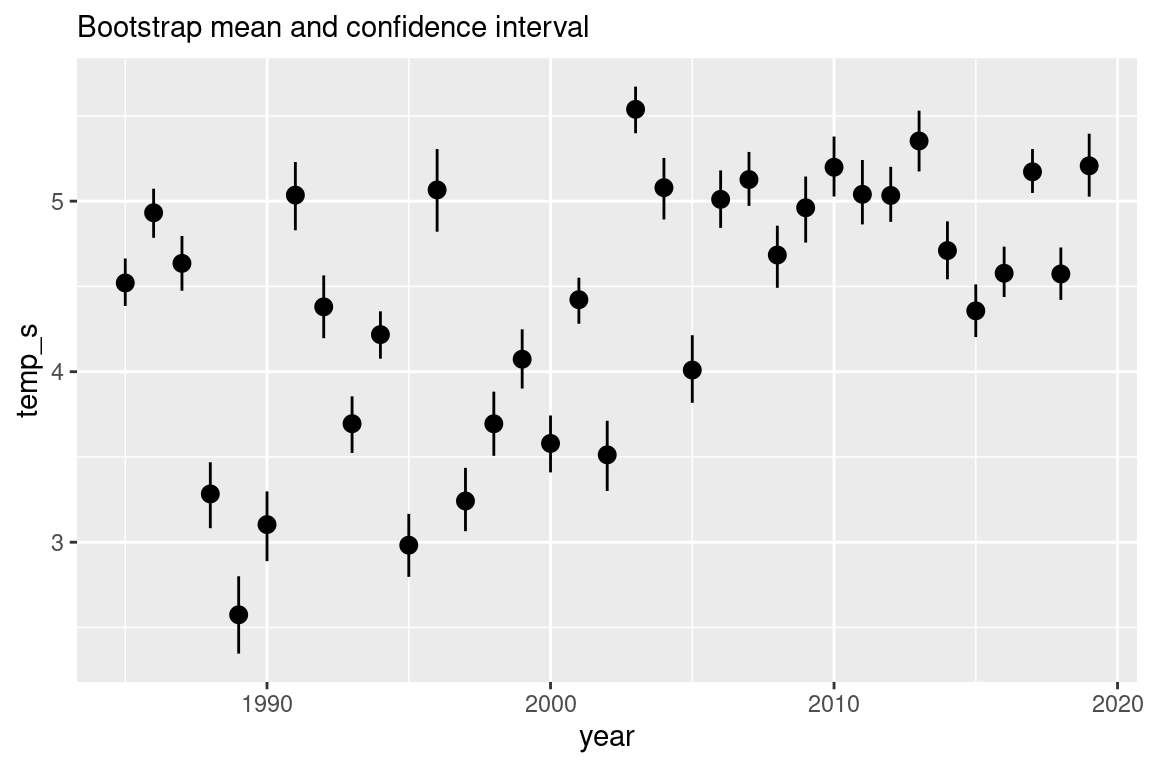
# Summary geoms ---------------------------------------------------------------## Surface temperature over time -----------------------------------------------s |>filter(!is.na(temp_s)) |>ggplot(aes(year, temp_s)) +stat_summary(fun.data ="mean_cl_boot") +labs(subtitle ="Bootstrap mean and confidence interval")
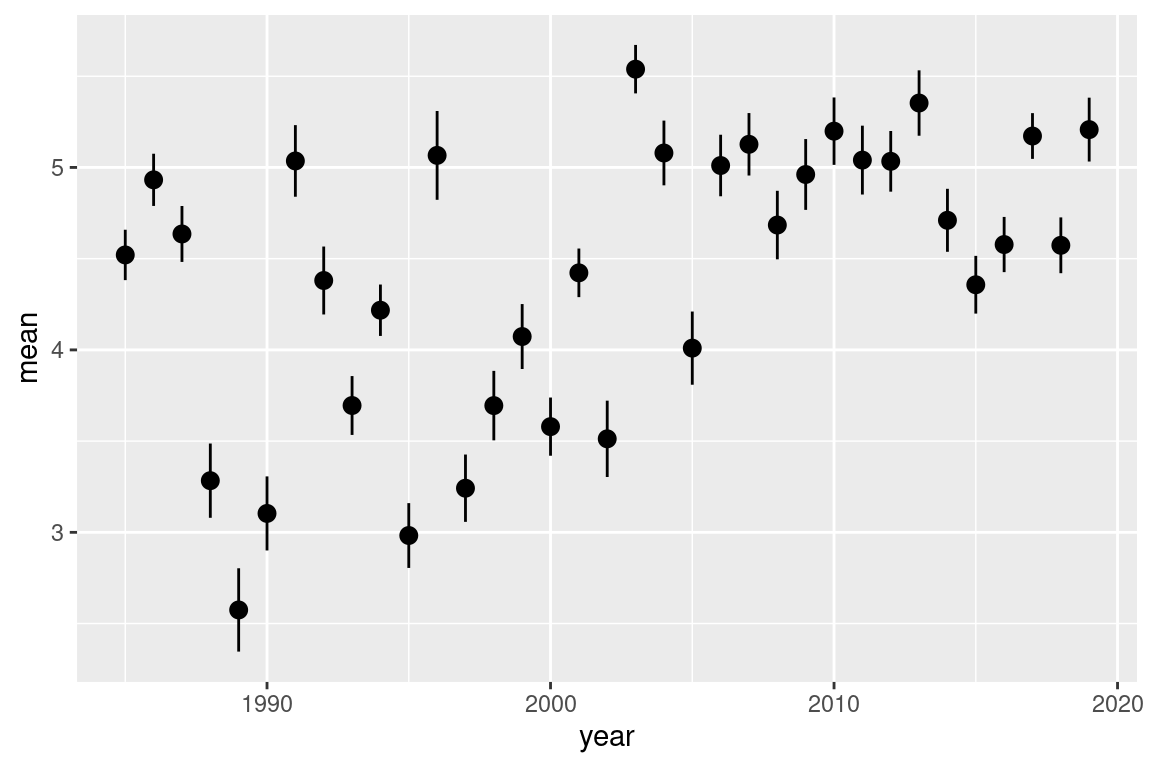
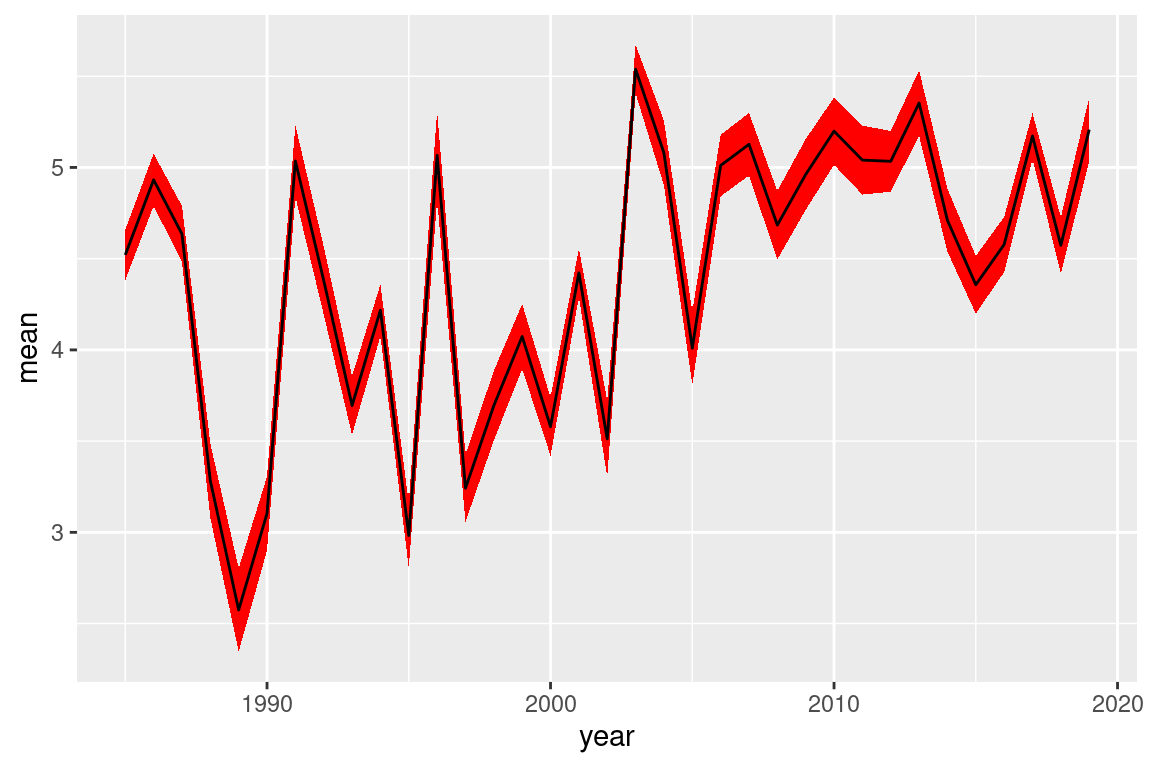
# could also dotmp <- s |>filter(!is.na(temp_s)) |>group_by(year) |>summarise(n =n(),mean =mean(temp_s, na.rm =TRUE),sd =sd(temp_s, na.rm =TRUE),se = sd /sqrt(n))tmp